News APIs, regulatory filings (SEC EDGAR, SEDAR+), patent databases (USPTO, WIPO), and financial disclosures — normalized into one schema with full provenance.
MVP Stage
Surveil
External Signal Intelligence for Competitive and Regulatory Monitoring
Competitive intelligence shouldn't run on Google Alerts. Surveil ingests news, regulatory filings, patents, and financial disclosures, resolves entities across sources, and surfaces the signals your team would otherwise miss.
Request Early Access
Product Preview
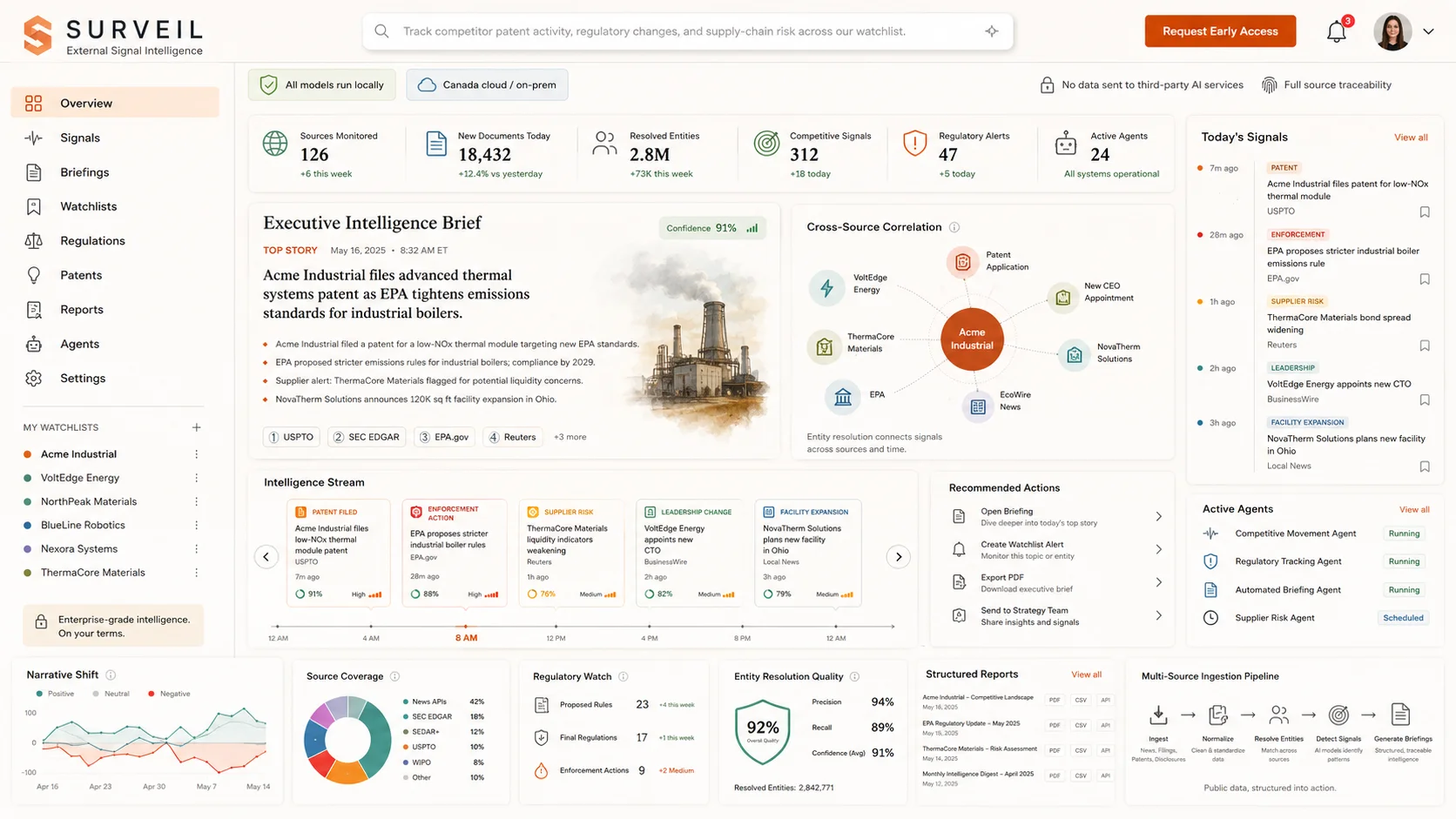
The Surveil Console
A live signal feed, entity graph, and structured intelligence — shaped to each client's sources, watchlist, and reporting cadence.
Capabilities
What Surveil Does
The same competitor mentioned in a filing, a news story, and a patent application is recognized as one entity. AI correlates signals across sources and timelines.
Product launches, leadership changes, partnerships, regulatory actions, and financial events — classified by type, confidence, and competitive relevance.
Watch how companies, products, and topics are discussed over time. Detect statistically significant shifts before they show up in market reaction.
Competitive briefings, market intelligence, and risk assessments assembled from the full corpus — delivered on schedule with full source traceability.
Agent Layer
Automate With Custom Agents
Competitive Movement Agents
Scan ingested sources for product launches, leadership transitions, and partnership announcements — surfaced as structured alerts with source documents attached.
Regulatory Change Agents
Watch filing systems and enforcement databases for proposed rules and actions affecting your industry or watchlist — with impact analysis mapped to relevant entities.
Briefing Generation Agents
Assemble competitive briefings and regulatory watch summaries on a defined schedule — pulled from the full corpus and distributed without manual assembly.
Who This Is For
Built for Teams That Track the Outside World
For teams where missing a public signal has real operational cost.
Corporate Strategy
A systematic view of competitive activity, patent filings, and market positioning — not a weekly roundup of Google Alerts.
Investment Research
Surface signals from regulatory filings, news, and patents before they are reflected in market pricing — so analysts spend time on analysis, not collection.
Regulatory and Compliance
Monitor regulatory developments, enforcement actions, and policy changes across agencies — with impact analysis mapped to your entities.
Request Early Access
Surveil is in MVP. We're working with design partners to define the source integrations and signal taxonomies — bring us your requirements.
Get in Touch